

はじめに
こんにちは、株式会社 Village AI 取締役副社長 松本 祐輝です。
本シリーズでは、日本酒アプリ「さけのわ」のデータをDataikuで分析してみたいと思います。
今回は、前回読み込んだデータの可視化とクラスタリングをやってみます。
前回の記事
さけのわデータ分析:クラスタリング編
データの可視化
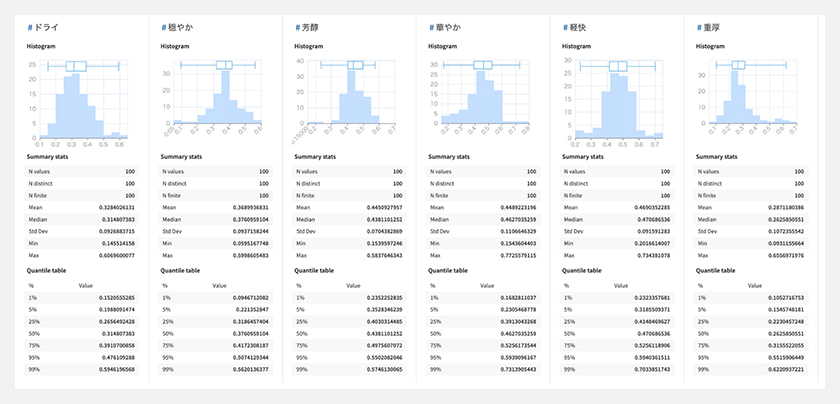
Statistics機能を使って、フレーバーの分布や相関関係を可視化します。
フレーバーのヒストグラム
フレーバーの相関係数行列

多変量分析として、主成分分析を実行してみました。
これもポチポチでできちゃうので楽ちんですね。
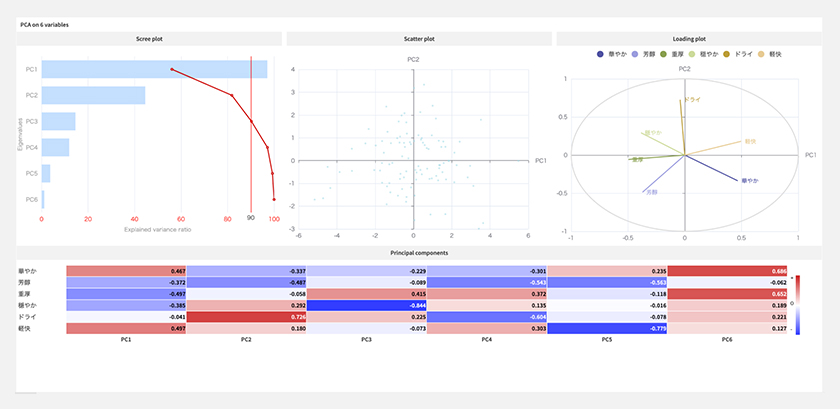
どうやら、3次元で90%の情報量があるみたいです。
芳醇はあんまり銘柄間で差がないってことなのかな?
PC1:華やか、軽快
PC2:ドライ
PC3:重厚、−穏やか
クラスタリング
銘柄をフレーバー情報を使って、クラスタリングを実行します。
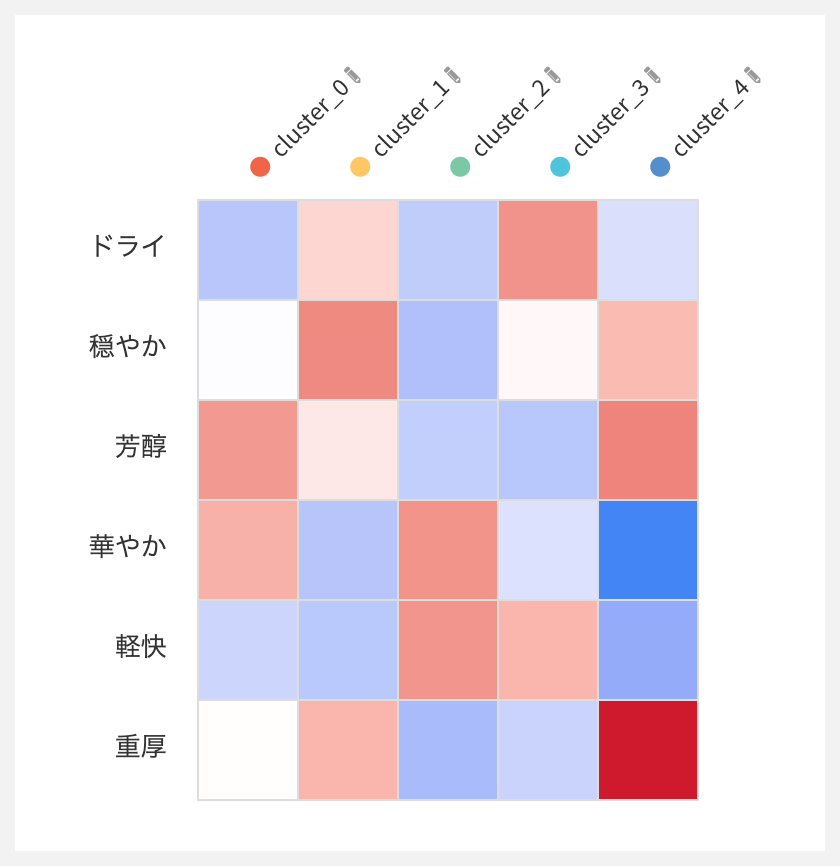
結果は、下図のようになりました。
クラスタ0:芳醇、クラスタ1:穏やか、クラスタ2:華やか軽快、クラスタ3:ドライ、クラスタ4:重厚
結構良い感じに分類出来ているように見えます!
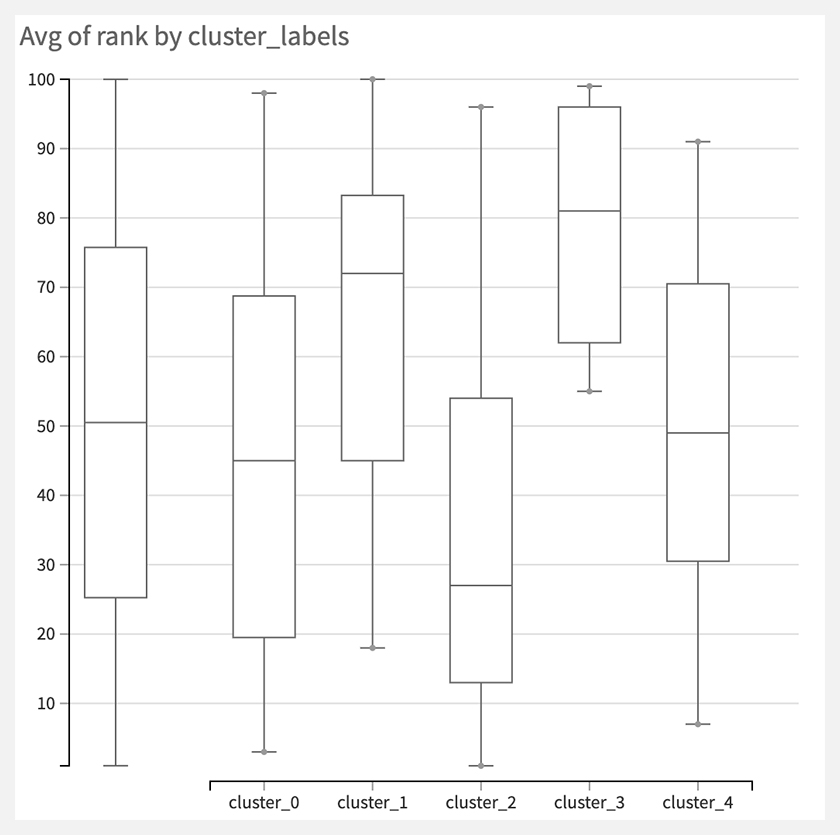
クラスタ別のランキングをみてみると、クラスタ2が高いようです。
(ランキングなので上下逆でわかりにくい・・・)
華やかとか軽快なやつが人気で、ドライはあんまり人気ないみたいですね。
おわりに
今回は、前回作成したデータの可視化及び統計解析を実行しました。
フレーバーの分布の確認や、フレーバー間の相関係数の確認、
主成分分析でデータの特徴をざっくり把握した上でクラスタリングを実行しました。
次回は、フレーバータグ分析をやってみたいと思います。
コメント